 即刻后端Newsletter
即刻后端Newsletter这个专栏用来分享即刻后端团队日常工作中的技术讨论和阅读分享,主要内容摘选自Slack中的发表和评论。如果对某条内容有什么想法,也欢迎大家通过回复邮件来参与讨论。
一次关于bson objectId valid的讨论,评论内容只选了一部分
呆唯:把用户昵称识别成objectID了
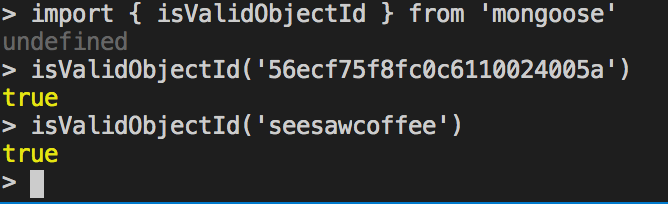
Sean:
bson 的 ObjectId.isValid() 应该不会把
panqianyu:
话说这个好像就是合法的 objectId
ziyu:
12 bytes in length
WangSiyuan:
lib/index.js:993-995
if (typeof v === 'string' && (v.length === 12 || v.length === 24)) {
return true;
}
zhangxuhui:
被坑过。。。
用的这
ObjectId.isValid(id) && new ObjectId(id)).toString() === id
Renzh:
12 bytes in length 应该是指二进制表示,这样的话没毛病
Renzh:
我们其实是想要一个ObjectId.isValidHexString()
ziyu:
类型是抽象概念
Sean:
就,为什么要支持这个string是个raw数据的可能
Sean:
但我们/这个库也是运行在这个抽象层面上的
ziyu:
socket
Sean:
socket拿到的不是buffer么?
ziyu:
buffer也是抽象概念
Sean:
不能因为是抽象概念就忽略
WangSiyuan:
https://github.com/Automattic/mongoose/issues/1959
#1959 Best way to validate an ObjectId
I'm inserting some objectIds as references and I want to make sure that they are valid objectids (right now I'm getting a crash when they aren't valid ids).
I'm checking to see if they refer to valid objects by just doing a find() call.
How should I check if the strings are in the correct format? I've seen some regexs that check if the string is a 24 character string and stuff like that - seems like a hack. Is there an internal validator on the ObjectId? I couldn't figure out how to use it. Thanks so much!
WangSiyuan:
an Object ID is any 12 byte long value so any 12 byte long string is a valid ObjectId
Sean:
如果说因为底层是一样的就可以把两种类型混为一谈或者忽略类型,那从一开始就不要分开类型好了,像C++一样都是u8[]
WangSiyuan:
就objectId的问题,就是任意12字节的值,都认为是objectid
ziyu:
是这个理解的
ziyu:
string 只是对12字节值的一种表征方式
Renzh:
我们是把ObjectId.isValid()当ObjectId.isValidHexString()用了
Sean:
是但是我们的工作是建立在这种表征方式之上的
Sean:
我们是在处理string or buffer
Sean:
不是在处理12个字节
WangSiyuan:
我们是把ObjectId.isValid()当ObjectId.isValidHexString()用了
是的,问题在这
ziyu:
c/c++程序员不是这么想问题的
Sean:
我们不是c/c++程序员
Sean:
这个库也不是写给c/c++用的
WangSiyuan:
24位hex字符串是对于我们目前的使用场景吧。
可能对于mongo/mongoose这种库,在 isValidObjectID 这个API上,可能还是符合官方定义比较好。可以再有一个 isValidHexString 方法来针对字符串判断 ^[0-9a-fA-F]{24}$
WangSiyuan:
另外bson本身就是二进制的,所以以12字节来定义objectID也算合理吧
至于库为什么用 12bytes 。我觉得是因为使用的是BSON类型,而不是JSON类型。
BSON本身就是二进制的格式(虽然日常使用感受不到他的二进制),所以里面的每个字段都是以二进制表现的。
http://bsonspec.org/spec.html
ziyu:
用24个字节去处理12个字节问题才是不科学的思考方式。不管什么语言程序员,第一堂课肯定会是类型以及其对应的存储空间吧。存储是很重要的,不能因为语言特性就忽略了这个。
Sean:
bson本身就是二进制
显然
所以以12字节来定义objectID也算合理吧
错误的推导
Sean:
也许isValid本身就是个错误
Sean:
但用string来表示二进制(非base64的string)也一定是个错误
Sean:
知道其背后的存储结构不代表你就应该绕过前面的抽象,一个非string的二进制数据用 二进制对应的string来表达和传递,这对应到c/c++里就是强制类型转换,从来就不是一件正确的操作
Sean:
bson可以fromString,这个string在几乎所有语境下都是hexString。在这个大前提下如果真实想用二进制底层数据来表示,在node的语境下就应该用buffer。
如果说因为底层一样所以就可以换着用,那我是不是还可以用string来代表object?
Sean:
我的这个观点建立在ObjectId的toString语义只有hex string一种的前提下,如果说其实不是这样的官方就是说其实有两种,那我只能说好吧,这很傻,我没办法。
但我不可能认同因为他底层一样因此就是一个东西这样的观点
一个mongo driver导致的内存泄露问题
panqianyu:
这段时间即刻部分服务出现了缓慢但明显的内存泄漏。通过对比服务的每小时内存快照,发现是因为 mongodb driver 的 replica set topology 根据 node timer 的 _called 字段,判断是否需要销毁定时器。但是在 node12 当中,此字段被移除了,导致定时器无法被销毁。
参见相关 issue 和源码
解决方法就是及时升级新版 mongodb/mongoose 库,以及开启 useUnifiedTopology
修改之后的服务,目前为止内存用量平稳
👍18
胖虎发布了一个redis管理工具,使用和mongood同样的技术开发
Renzh:
一个Redis GUI:
https://github.com/RenzHoly/sider
👍7
0neSe7en在后端周会上的分享
https://staffeng.com/guides/staff-archetypes 这个系列文章以及作者的博客值得一看。作者是Calm的CTO。
这篇文章把工程师的发展方向分成四个类别,觉得很恰当:
Tech Lead:一般来讲和一个Manager合作,带领一个小团队去完成任务等等。
Architect架构师:负责在某些关键领域设置方向、质量评估、以及实现方法。会综合技术限制、用户需求、组织内的Leader等
Solver问题解决者:一般是去深入解决一个复杂的问题,找到解决问题的方向。一般来讲找到解决办法后,就会去解决下一个问题。然后把这些方法交给其他团队继续维护和迭代。
Right Hand右手:就类似权游的那种
关于年龄焦虑,尤其是国内的35岁焦虑
最近看到rsms从figma离职,就去看了一下他的博客,发现他很酷。http://rsms.me/
99年毕业从事设计工作,作为设计师工作了七年。
2006年(30多岁)去了Spotify作为初始员工之一,当设计负责人。在Spotify也做了一些C++的工作,写了高性能的后端和一些基础设施,也是Nodejs早期的核心开发者。
四年后(35岁吧)离开Spotify去了Facebook当设计师,在Facebook期间,是iOS/Messenger/Facebook Home等产品的设计师,也是开发,还参与创造了GraphQL。
然后13年去了Dropbox,工作了两年半。
然后2016年去了Figma(40多岁),那时候Figma刚开始不久。比如一起设计了Figma的Logo以及编辑器等等。
同时也在探索wasm、编译器、编程语言等等东西。